Delay of DeepSeek V4 and the Cost of Transitioning AI Computing Platforms
As we enter 2026, the release window for DeepSeek V4 has been repeatedly postponed, unexpectedly igniting discussions in the global AI community about moving away from CUDA. Reports indicate that this multimodal open-source model, expected to have a trillion-parameter scale and support for million-token contexts, is being adapted for Huawei’s Ascend chips, with core code being rewritten through the CANN framework.
If this becomes a reality, it will mark the first systematic exploration of core model capabilities on non-CUDA platforms within China’s AI ecosystem. In other words, this is not just a model release but a “stress test” of underlying technological routes.
However, as DeepSeek founder Liang Wenfeng emphasized in internal communications, this is merely the “first step in a long march.” Future risks and opportunities coexist, and the balance between compatibility and independence will determine whether China’s AI can truly carve out its own developmental path.
The Inevitable Cost of Transitioning AI Computing Platforms
As mentioned, the V4, originally planned for release around the Lunar New Year or in February-March, has missed its window, with media confirming a release in early April. The reason lies in the deep adaptation required for inference on Huawei’s Ascend chips. However, this path is far more complex than anticipated. To understand this complexity, we must first look at the technical characteristics of DeepSeek V4 itself.
By 2026, large model parameter scales have crossed the trillion mark and are moving towards tens of trillions. In this context, while V4 adopts a more aggressive MoE (Mixture of Experts) architecture to theoretically reduce the computational load per inference by “activating experts on demand,” it demands extreme capabilities from the system in terms of memory bandwidth, inter-chip connectivity, and KV Cache management.
In other words, the pressure on computing power has shifted from pure computation to system scheduling and communication. Within the NVIDIA ecosystem, there are relatively mature solutions to these problems.
For example, high-bandwidth interconnects built using NVLink and NVSwitch based on H100 or B200 can achieve TB/s-level bandwidth between GPUs in a single node, forming a nearly “fully connected” computing network where data flows between chips like a highway, significantly reducing latency and synchronization costs. However, when DeepSeek attempts to migrate this sophisticated system to the Huawei Ascend platform, it faces a completely different hardware topology.
Undeniably, Ascend chips have made significant progress in recent years, but they still lag behind NVIDIA in terms of “fully connected capabilities” for ultra-large clusters. For instance, constrained by manufacturing processes and SerDes IP capabilities, Ascend relies more on optical modules for cross-node expansion. This “trading space for bandwidth” solution, while feasible, introduces longer physical links, leading to signal delays, synchronization overheads, and complexities in power and heat management.
At the same time, the software gap is equally significant. The CANN framework on Ascend still lags behind the CUDA ecosystem in terms of operator coverage, automatic parallelism, kernel fusion, and distributed communication scheduling. This means that the DeepSeek engineering team must perform targeted optimizations on numerous low-level details and even manually rewrite key operators.
The more challenging aspect is that this lag is often not linear but systemic. A performance drop in one operator can affect the entire computation chain; a reduction in communication efficiency can lead to significant fluctuations in overall throughput. The final result may be that the model can still run, but it is far from stable, efficient, and scalable.
From this perspective, the delay of DeepSeek V4 is not merely a product rhythm issue but the inevitable cost of deep integration between China’s top algorithm teams and domestic chip systems. Although the process is arduous, it is of great significance.
More importantly, this process sends a clear signal that AI competition is shifting from “model capability comparison” to “system engineering capability comparison.” At this stage, those who can run models quickly, stably, and cost-effectively are the ones who truly approach industrial-level advantages.
Breaking CUDA’s Monopoly: CANN’s Reluctant Compromise
If the adaptation difficulties of DeepSeek V4 on the inference side reveal engineering bottlenecks, a more fundamental question arises: why is it so difficult to migrate a model from one computing platform to another?
Looking back at the PC era’s Wintel alliance, although Microsoft and Intel monopolized the market, there was a power struggle between the two companies, leaving room for the rise of Linux, AMD, and even Apple systems. However, NVIDIA has established a form of “monolithic vertical monopoly” in the AI field, akin to a combination of Microsoft and Intel.
This is reflected in the hardware layer, where NVIDIA defines the physical structure of SM (Streaming Multiprocessor) and the computational logic of Tensor Cores; on the software side, CUDA provides perfectly matched closed-source libraries like cuBLAS and cuDNN. The combination of these two aspects has led to a terrifying reality: over 6 million developers globally optimize algorithms and frameworks (like PyTorch and TensorFlow) primarily for CUDA implementations, even AWS Trainium and Cerebras WSE’s “anti-NVIDIA” heterogeneous clusters still require NVIDIA NIXL software and AWS EFA for KV cache migration.
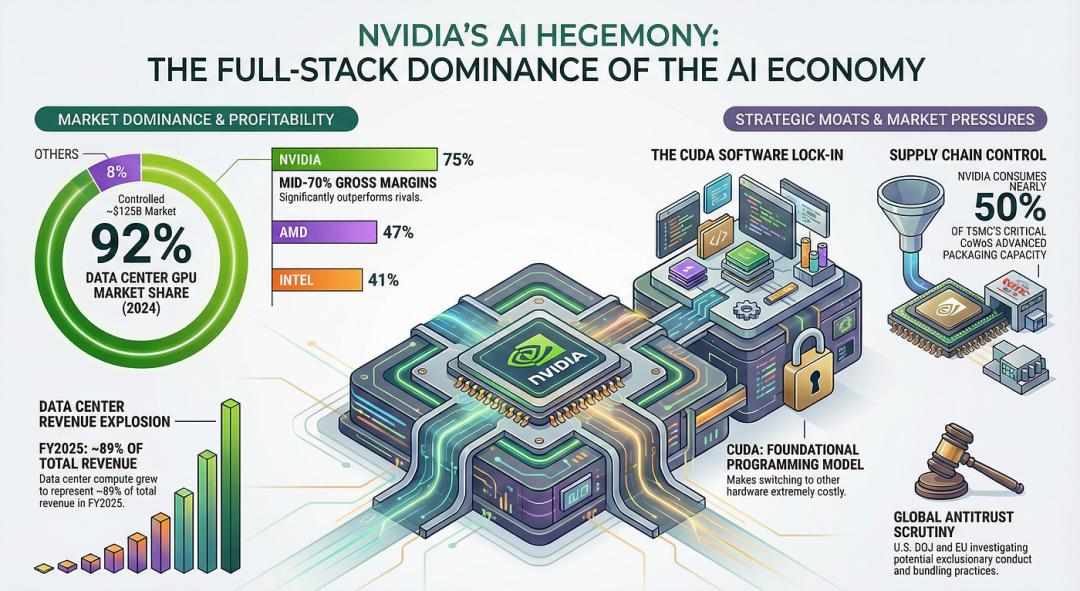
This is not merely a technical detail but an ecological lock-in, where the failure of model portability means that developers have become accustomed to thinking in terms of NVIDIA hardware features. This ecological inertia has allowed NVIDIA to absorb over 90% of global innovation dividends.
In this context, Huawei’s CANN, as its strongest competitor, initially attempted to pursue a relatively independent route. However, with the advent of large models, this path has gradually revealed issues, such as developers’ reluctance to migrate, companies’ fear of taking risks, and slow ecological growth. Coupled with the pressure of time (e.g., rapid iteration of large models), a completely independent path has begun to seem unrealistic.
As a result, CANN has gradually introduced a design similar to CUDA’s abstraction layer, attempting to match cuBLAS and cuDNN interfaces in CANN Next, achieving a high degree of compatibility and compressing model migration costs from “weeks or even months” to “hours.” At the architectural level, the newly released 950PR heterogeneous architecture (pre-fill/decode decoupling) intentionally mimics NVIDIA’s decoupled service rather than Google’s TPU’s completely heterogeneous route.
We must acknowledge that this “compatibility-first” strategy has been successful in the short term, lowering barriers and allowing Ascend to rapidly gain a foothold in the domestic market, enabling companies like DeepSeek, Tencent, and ByteDance to experiment with domestic computing power at a lower threshold. For instance, CANN Next achieves over 95% CUDA compatibility through the SIMT programming model, significantly reducing migration time for many companies to just hours, accelerating practical implementation.
However, the accompanying challenge is that once it involves cutting-edge innovations, the compatibility layer can become a “ceiling.”
For example, when developers delve deeper into using the Ascend platform, they find that while common paths have been paved, once they attempt some niche or innovative low-level operators, CANN’s support tends to decline, leading to severe performance fluctuations. During the adaptation process of DeepSeek V4, challenges arose when trying to introduce hybrid architectures like SSM (State Space Model) or Mamba, revealing that CANN’s underlying optimizations still primarily lean towards matrix multiplication (GEMM). This difficulty largely stems from hitting the “boundary” of CANN’s compatibility layer when attempting some unconventional algorithm optimizations.
A deeper issue is that once compatibility is chosen, it implicitly assumes that CUDA remains the invisible standard. You can replace hardware, but in terms of software semantics and development paradigms, you still adhere to the rules defined by the other party. This is both a shortcut and a limitation.
Compatibility Challenges and Future Opportunities for True Independence
As mentioned, given the reality of CUDA’s ecosystem forming a de facto standard, Huawei’s choice of a “compatibility-like” path is almost inevitable. However, this also places the entire Chinese AI industry at a critical decision point: whether to continue to be compatible with CUDA or gradually move towards a truly independent ecological system.
In the short term, the answer is almost certain: compatibility is a necessity, a choice driven by efficiency and reality. However, in the long term, this path harbors significant risks.
It is well known that when a system (like CANN) is designed to be compatible with another system (like CUDA), it inevitably inherits the limitations of the latter.
Currently, most open-source algorithms globally are developed around the NVIDIA architecture. If we pursue 1:1 compatibility solely to leverage these existing assets, we risk falling into a “imitator’s trap” in hardware design. This would manifest as a sudden technological gap if NVIDIA’s hardware architecture undergoes a paradigm shift in the future, such as moving from Transformer to a new architecture that does not require large-scale matrix multiplication but relies more on asynchronous logic. The domestic computing stack, which has remained in a “shadow state,” could face an abrupt technological disconnection. This “Bug-for-Bug compatibility” deadlock would undoubtedly keep our foundational innovations overshadowed by others.
A deeper risk lies in the “time lag.” According to statistics from Bernstein and Epoch AI, while Huawei’s domestic market share has surged, its share of global AI computing power remains only 5%, which is relatively limited. This absolute scale gap leads to severe “R&D efficiency friction.”
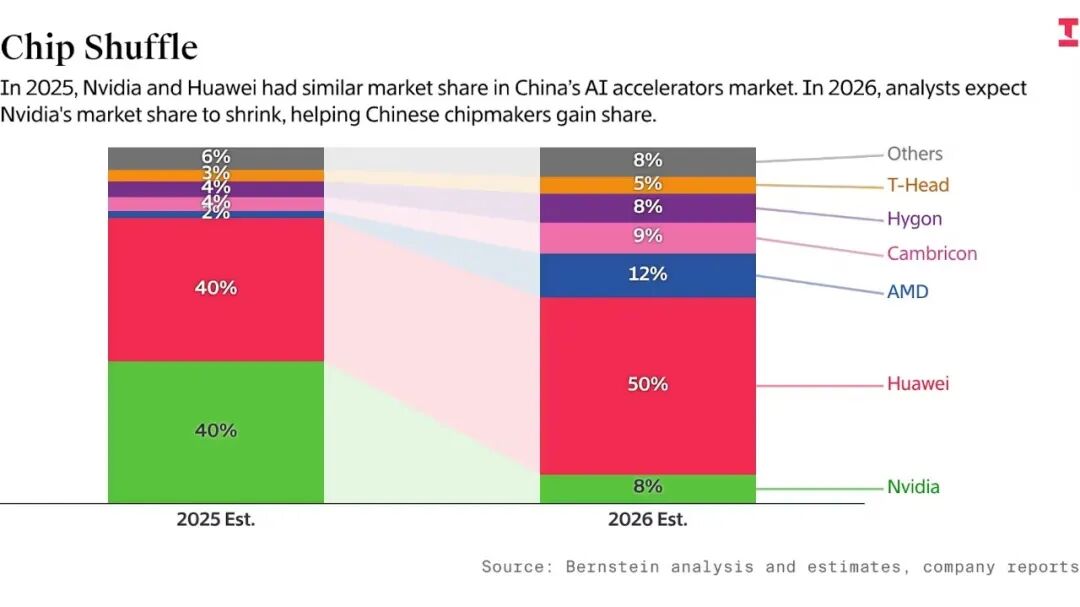
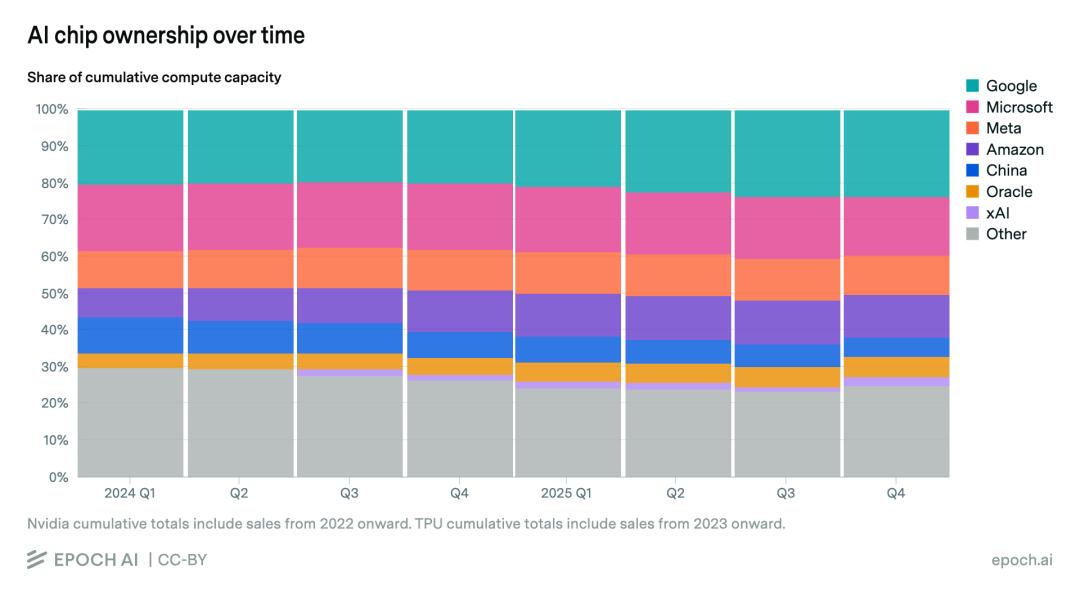
Specifically, American AI giants can leverage the powerful communication bandwidth of Blackwell to run 10T parameter Scaling Laws in 18 months, while top talents in China must expend over 50% of their research capacity on issues like “how to solve signal degradation in outdated chips” and “how to adapt to immature compilers.”
It should be noted that this temporal misalignment can be amplified in the rapidly changing AI era. While our talents are busy “filling pits,” competitors may have already achieved exponential returns in model capabilities, resulting in a gap that evolves from a year of model capability, data flywheel, and safety alignment into a multi-year chasm.
Of course, challenges often contain opportunities. If DeepSeek V4 is successfully released, it will prove the feasibility of a “domestic full stack,” accelerate the maturation of the CANN ecosystem, attract more developers, and coupled with the global sentiment of “the world has long suffered from NVIDIA,” support for CANN may exceed expectations. If subsequent chips from Huawei’s Ascend achieve 80%-90% of H100’s inference performance, combined with the compatibility benefits of CANN Next, the critical scale of China’s AI supply chain could form within 1-2 years.
However, it is crucial to recognize that compatibility can only address the issue of “survival,” while true independence will determine “how far we can go.” The next 3-5 years will be a critical window. If we can gradually establish independent programming models, operator systems, and system architectures while maintaining compatibility, China’s AI ecosystem still has the opportunity to leap from following to defining the rules. Otherwise, Chinese AI may fall into the track of “rough copying trains.”
In conclusion, the delay in the release of DeepSeek V4, seemingly an incidental “missed deadline,” actually reveals a deeper reality: AI competition is no longer just a battle of models but a comprehensive contest of underlying ecosystems and system capabilities. While compatibility with CUDA is undoubtedly the shortest path to reality, stopping there may also lock in future ceilings.
Thus, the real challenge lies not in whether one can replace a set of technologies but in whether one can break free from reliance on existing paradigms and build a rule system of their own. The next 3-5 years will determine whether China AI becomes a significant player in the global ecosystem or remains in a position of “high-level following” for the long term. Of course, in the pursuit of independence, we must also be wary of the potential impact of a closed ecosystem on the attractiveness to global developers, ensuring the openness and long-term international competitiveness of the ecosystem.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.